El tiempo medio entre fallos (MTBF) es una métrica crucial para cualquier industria en la que los fallos de los equipos pueden provocar costosos tiempos de inactividad, problemas de conformidad o problemas de seguridad. En este artículo, analizaremos el significado de MTBF, cómo puede mejorar las prácticas de mantenimiento y cómo calcularlo a través de un ejemplo del mundo real.
¿Qué es el tiempo medio entre fallos (MTBF)?
El tiempo medio entre fallos mide la vida productiva prevista de un sistema, activo o componente. Calcula el tiempo medio de funcionamiento ininterrumpido de los equipos entre averías.

El MTBF es una medida crucial para ayudar a las empresas a controlar la disponibilidad de los equipos. También es una forma útil de evaluar la fiabilidad general de una planta o instalación.
El seguimiento del MTBF ayuda a los responsables de mantenimiento a planificar y programar las tareas de mantenimiento con mayor eficacia. Si se utiliza correctamente, el MTBF también puede ayudar a los equipos a predecir cuándo necesitará mantenimiento un activo.
Esto significa que los activos reciben rápidamente las reparaciones que necesitan para seguir funcionando, lo que se traduce en un tiempo de inactividad mucho menor. El MTBF es una métrica clave en entornos industriales, donde el tiempo de inactividad puede hacer descarrilar la producción y aumentar los costes. El MTBF también puede reducir los costes de mantenimiento ayudando a los equipos a establecer prioridades de mantenimiento.
Sin embargo, también es importante reconocer las limitaciones del MTBF. En general, la métrica es muy precisa y procesable, pero el tiempo medio entre fallos nunca debe utilizarse como garantía de fiabilidad. Incluso un activo con un MTBF muy alto puede sufrir un fallo repentino e inesperado.
También conviene tener en cuenta que el tiempo medio entre fallos puede variar en función del tiempo de funcionamiento, los factores ambientales y las condiciones de uso. Al igual que otras métricas, el MTBF necesita datos actualizados y de alta calidad para ser eficaz.

Cómo calcular el tiempo medio entre fallos: ¿Qué es la fórmula del MTBF?
La fórmula del tiempo medio entre fallos es sencilla, por lo que los cálculos del MTBF son fáciles de realizar en la propia empresa. No confíe en la estimación de un fabricante para conocer el MTBF de un activo: es mejor utilizar datos de la máquina real para determinar esta métrica.
El tiempo medio entre fallos es muy variable y depende de las condiciones de funcionamiento específicas del activo, de su utilización y de otros factores. Por eso es esencial calcular el MTBF a partir de los datos obtenidos directamente de sus activos.

Para calcular el MTBF, necesitará conocer el número total de horas que una máquina o componente ha estado en funcionamiento. También necesitará saber el número de veces que el activo ha fallado durante ese periodo de tiempo.
Una vez recopiladas estas mediciones necesarias, puede aplicar la fórmula MTBF. La fórmula funciona dividiendo el total de horas de funcionamiento del activo por el número de veces que falló en ese periodo.
La fórmula utilizada para calcular el tiempo medio entre fallos (MTBF) es:
Horas de funcionamiento / Número de fallos = MTBF
Guía paso a paso para calcular el tiempo medio entre fallos
Para calcular el MTBF sólo hay que seguir tres pasos.
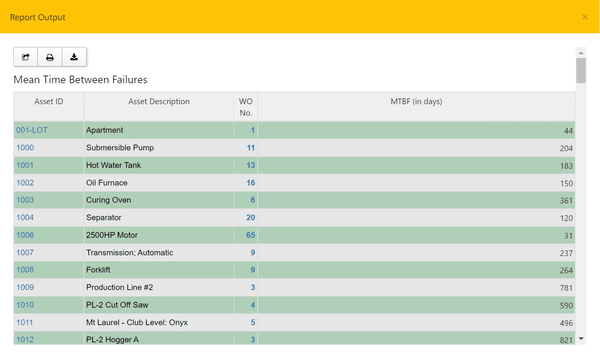
Primer paso: Determinar el total de horas de funcionamiento del activo en cuestión. Su sistema informático de gestión del mantenimientoGMAO) ya debería hacer un seguimiento de las horas de uso, por lo que recopilar estos datos debería ser fácil. Si no, puede utilizar los registros de uso de los activos y las órdenes de trabajo para calcular el tiempo de actividad de la máquina.
Segundo paso: Averigüe el número de fallos que se han producido en el activo durante el tiempo de funcionamiento. Si no está seguro de la tasa de fallos, utilice la función de informes de su GMAO. El historial del sistema de gestión de órdenes de trabajo y los programas de mantenimiento proporcionarán datos suficientes para averiguar el número total de averías.
Tercer paso: Calcular el MTBF mediante la fórmula. Tome el número total de horas de funcionamiento y divídalo por el número de fallos para obtener el número medio de horas de funcionamiento entre fallos.
Este es el cálculo del MTBF en la práctica:
Cómo calcular el MTBF: un ejemplo real
Imaginemos que una bomba funciona durante 1.000 horas y se avería cuatro veces. Utilizando la fórmula, calcularía el MTBF del activo como:
1000 horas de funcionamiento / 4 averías = 250
El tiempo medio entre averías de esta bomba sería de 250 horas.
La fórmula MTBF es sencilla, pero requiere muchos datos precisos. Por eso GMAO cambia tanto las reglas del juego en el seguimiento del MTBF y otras métricas. Los programas GMAO actúan como un repositorio centralizado de todos los datos de una planta, como las horas de funcionamiento y el número de fallos. Almacenan toda la información crítica en un lugar de fácil acceso.
Un GMAO también facilita el acceso remoto a los datos que necesita. También realiza un seguimiento automático de muchas métricas para que pueda ver rápidamente las tendencias a lo largo del tiempo, lo que facilita la gestión de los ciclos de vida de los activos y el inventario.
¿Por qué es importante calcular el MTBF?
El MTBF es un parámetro importante que los equipos de mantenimiento deben tener en cuenta para reducir el tiempo de inactividad y prolongar la vida útil de los activos. Conocer el tiempo medio entre fallos proporciona a los responsables de mantenimiento información sobre el estado de los activos, lo que les ayuda a realizar predicciones informadas sobre las necesidades futuras de mantenimiento.
El seguimiento del MTBF ayuda a los equipos:
- Determinar las áreas de riesgo y planificar estrategias para proteger los activos críticos.
- Evaluar la eficacia de las estrategias y los flujos de trabajo de mantenimiento
- Tomar decisiones informadas sobre la sustitución o reparación de equipos
- Mejorar la gestión de inventarios y piezas de recambio
El coste de un tiempo de inactividad imprevisto puede ser devastador. Pero cuanto más sepa sobre el MTBF, más fácilmente podrá evitar las averías.
Overcoming the Challenges of MTBF Calculation
Calculating MTBF is a powerful way to assess equipment reliability, but the challenges teams face when calculating it can skew results or limit its effectiveness. Tackling these obstacles will ensure your team has accurate MTBF metrics. And once you have accurate metrics, you can take steps to enable better maintenance planning and reduce downtime.
Calculating MTBF: Common Challenges
- Data Availability and Quality
MTBF calculations require precise data on operational hours and failure counts. Incomplete or inconsistent data can lead to unreliable results from the MTBF formula. For example, if failure logs are missing or uptime records are inaccurate, your MTBF may misrepresent an asset’s true reliability.
- Short or Inconsistent Time Frames
MTBF calculations over short periods may not reflect long-term reliability trends. For instance, a pump tracked for one month might show a high MTBF due to having few failures, but a year-long analysis could reveal frequent issues. Inconsistent time frames also complicate comparisons across assets.
- Changing Operating Conditions
Environmental factors like temperature, humidity, or vibration, as well as usage patterns (for example, increased usage during seasonal production fluctuations), can significantly affect failure rates. If these conditions change, historical MTBF data may no longer be accurate, complicating predictions.
Despite the potential challenges of calculating MTBF, there are several strategies organizations can use to measure and track MTBF effectively.
Strategies To Overcome MTBF Calculation Challenges
- Leverage a CMMS for Accurate Data Collection
A robust CMMS automates data collection for operational hours and failure events, ensuring high-quality, real-time data for use in the MTBF equation. Features like automated work order tracking and sensor integration eliminate manual data entry errors. Reporting tools that log every failure and uptime period provide reliable data for MTBF calculations without relying on manual recording or calculations.
- Use Consistent and Representative Time Frames
Choose a time frame that reflects the asset’s typical operating cycle. Ideally, the time frame will be a year or more for stable trends. Document the time frame used in calculations to ensure consistency across reports. For seasonal equipment, adjust calculations to account for active vs idle periods. When tracking MTBF with a CMMS, you can easily adjust the reporting timeframe for different time periods to highlight short-term issues, long-term trends, or seasonal variations without compromising consistency.
- Optimize Maintenance Schedules
Align preventive maintenance with MTBF trends to avoid over- or under-maintaining assets. Use MTBF data to schedule maintenance just before expected failure points, reducing unnecessary interventions. A CMMS can automate these schedules based on real-time MTBF insights.
- Account for Operating Conditions
Track environmental and usage data alongside MTBF to contextualize results. For example, a pump in a highly humid environment may fail sooner than one in a controlled setting. Use sensors integrated with your CMMS to monitor conditions like temperature or vibration, adjusting MTBF expectations accordingly.
- Advanced Techniques: Using AI and Predictive Maintenance
More companies are integrating AI-driven predictive maintenance tools to improve MTBF results and support maintenance scheduling. These tools analyze historical failure data and real-time sensor inputs to predict when failures are likely. This allows teams to act before issues occur, increasing MTBF.
Why MTBF Results Change Over Time
No matter how robust your maintenance processes are, every machine will eventually experience failure. And over time, as machines age and accumulate wear and tear, it’s natural for more failures to occur and for MTBF to decrease. For example, a five-year-old pump will probably have a shorter MTBF than a brand new one, even if the pumps are from the same manufacturer and used in the same environment.
It’s important to consider the data you’re using in the MTBF equation and to plan how you’ll use that information. Let’s say you commissioned a new pump, and it ran for 4,000 hours before a single failure, while your five-year-old pump had five failures within the same timeframe. This doesn’t necessarily mean that your five-year-old pump needs to be replaced. However, comparing the MTBF of both pumps and trending the data over time can still give you actionable insight to use during maintenance. It can help you answer questions like:
- How often to perform maintenance based on the machine lifecycle
- How maintenance frequency should change over time
- When you should overhaul the machine to extend its lifespan and improve MTBF
- When the maintenance frequency becomes high enough to justify machine replacement
When looking at how to calculate MTBF trends over time, visualize them with tools like graphs or charts. For example, a line graph showing a machine’s MTBF declining from 4,000 hours to 800 hours over five years can highlight when to replace or overhaul it. A good CMMS can generate these visuals, making it easier to communicate trends to your team and make decisions that ultimately impact uptime and your bottom line.
Cómo y cuándo utilizar el MTBF
El tiempo medio entre fallos es uno de los indicadores clave de rendimiento (KPI) más utilizados en la gestión de activos. Esta métrica es muy valorada porque permite conocer la vida útil de un activo.
Cualquier organización que dependa de maquinaria compleja para cumplir sus objetivos se beneficiará del cálculo del tiempo medio entre fallos. El MTBF se utiliza en muchos sectores, pero es especialmente importante en industrias como:
- Automóvil
- Alimentos y Bebidas
- Ciencias de la vida
- Petróleo y Gas
- Minería
Por ejemplo, en la industria del automóvil, las organizaciones utilizan el MTBF para evaluar la fiabilidad de motores, transmisiones y componentes.
En el sector de la alimentación y las bebidas, los equipos de mantenimiento, reparación y operaciones (MRO) utilizan el MTBF para ayudar a mantener en funcionamiento los equipos de seguridad alimentaria. Esta métrica también es útil para mejorar la eficiencia energética al garantizar que los equipos que consumen mucha energía, como los frigoríficos, se mantienen en buen estado.
En el sector de las ciencias de la vida, los equipos utilizan el MTBF para aumentar la fiabilidad y mantener el rendimiento de los equipos en condiciones óptimas. Las ralentizaciones causadas por el mal funcionamiento de los equipos pueden dañar los lotes de productos o provocar retrasos costosos. Optimizar el rendimiento de los activos ayuda a evitar esas ralentizaciones y a garantizar una producción uniforme.
En general, los equipos de MRR utilizan el MTBF para:
- Evaluar el rendimiento de los activos
- Evaluar los puntos fuertes y débiles del equipo de MRR y medir la eficacia de las nuevas estrategias de MRR.
- Planificar programas de mantenimiento preventivo para que los equipos de mantenimiento realicen las reparaciones cuando sea necesario, en lugar de en un calendario arbitrario.
- Mejorar la gestión del inventario de piezas de repuesto para garantizar que las tripulaciones tengan siempre a mano las piezas que necesitan.
- Tomar decisiones basadas en datos sobre cuándo reparar o sustituir los activos, en función de la frecuencia y el coste de las reparaciones.
- Identificar los equipos y procesos que contribuyen a la pérdida de ingresos
Ventajas y desventajas de utilizar el tiempo medio entre fallos
El tiempo medio entre fallos es una métrica popular porque ha sido probada a lo largo del tiempo: Los equipos de MRR confían en sus resultados. Al mismo tiempo, cada KPI tiene sus desventajas. Estos son algunos de los pros y los contras del MTBF.
Ventajas de utilizar el MTBF para el mantenimiento y la fiabilidad
Calcular el tiempo medio entre fallos de un activo puede reducir drásticamente el tiempo de inactividad. El MTBF le da una buena idea de cuándo es probable que una máquina experimente problemas, de modo que su personal pueda realizar reparaciones con antelación y anticiparse a los fallos.
Del mismo modo, el MTBF ayuda a los equipos de MRO a planificar programas eficaces de mantenimiento preventivo (PM). El MTBF le permite saber aproximadamente cuánto tiempo durará un componente antes de tener que ser sustituido y cuánto tiempo puede funcionar una máquina antes de necesitar un mantenimiento rutinario. Esto también puede reducir sus costes de mantenimiento, ya que sus equipos no realizarán tareas de mantenimiento hasta que sean realmente necesarias.
El MTBF mejora la gestión del inventario al ayudar a los equipos a planificar exactamente cuándo deben tener piezas de repuesto a mano.
A largo plazo, el MTBF prolonga la vida útil de los activos y mejora la productividad. Los activos bien mantenidos tienen una vida útil más larga y rinden al máximo. Esto mejora la velocidad de producción y puede aumentar la calidad del producto.
Por último, el MTBF puede aumentar la seguridad, tanto en sus instalaciones como en sus productos. El mantenimiento basado en datos conduce a procesos estandarizados y predecibles, que producen condiciones más seguras en el lugar de trabajo porque hay menos margen para el error humano. En sectores como las ciencias de la vida y la alimentación y bebidas, unos activos bien mantenidos pueden suponer la diferencia entre unos productos seguros y de alta calidad y unos resultados inconsistentes que deben desecharse.
Desventajas de utilizar el MTBF como métrica de rendimiento
Dependiendo de las circunstancias, el MTBF puede ser difícil de calcular. Aunque la fórmula en sí es sencilla, se basa en datos a los que no todos los equipos pueden acceder. Si no se dispone de información precisa sobre el tiempo de funcionamiento o el número de fallos de un activo, es imposible determinar correctamente su tiempo medio entre fallos.
Del mismo modo, si los datos sólo cubren un breve periodo de tiempo, es probable que los resultados del MTBF no representen con exactitud el estado real del activo. El uso de un GMAO le garantiza que siempre tendrá acceso a datos fiables y precisos.
También es importante recordar que el MTBF es sólo una métrica: utilizado de forma aislada, no proporciona información suficiente para elaborar una estrategia de mantenimiento eficaz. Por ejemplo, calcular el tiempo medio entre fallos no indica la causa de cada fallo. Tampoco tiene en cuenta la gravedad de cada fallo ni el tiempo que se tarda en reparar el activo. Por eso es tan importante calcular el MTBF junto con otros KPI de mantenimiento.
KPI de mantenimiento relacionados
Para tener una visión completa del estado de un activo, es una buena práctica hacer un seguimiento de varios KPI a la vez. Estas son algunas de las métricas de mantenimiento estrechamente relacionadas con el MTBF.
Tiempo medio de reparación (MTTR)
El tiempo medio de reparación(MTTR) mide el tiempo que se tarda en reparar o restaurar un activo tras un fallo. Puede utilizar esta métrica para evaluar el estado general de un activo, ya que los equipos antiguos suelen tardar más en repararse. El MTTR es también una excelente manera de evaluar su programa de mantenimiento e identificar las áreas que necesitan mejoras.
Tiempo medio hasta el fallo (MTTF)
El tiempo medio hasta el fallo(MTTF) se confunde a menudo con el MTBF. Para ser claros, el MTTF es el tiempo medio que un activo no reparable permanecerá en funcionamiento antes de sufrir una avería. Esta métrica mide toda la vida útil de un activo antes de que sea necesario sustituirlo.
El MTBF, por el contrario, mide el tiempo que transcurre antes de que un activo necesite ser reparado.
Uptime
El tiempo de actividad es el porcentaje de tiempo que un activo está operativo. Se calcula dividiendo el número total de minutos de disponibilidad de la máquina por el número total de minutos de la jornada laboral (o de la semana, el mes o el año). El tiempo de actividad es una medida útil porque proporciona una visión rápida y general de la disponibilidad de un activo.
Eficacia de la producción
La eficiencia de la producción mide la eficacia con la que una organización utiliza los recursos de que dispone. Esta métrica es útil para conocer las prácticas de fabricación, la gestión del flujo de trabajo y los residuos. También puede suponer un fuerte incentivo para que los equipos introduzcan mejoras y les anime a fijarse más en otras métricas, como el MTBF.
¿Qué es mejor, MTTR o MTBF?
Ni el MTTR (tiempo medio de reparación) ni el MTBF (tiempo medio entre fallos) son intrínsecamente mejores. Cada uno sirve a un propósito distinto a la hora de evaluar la fiabilidad y el rendimiento del sistema. El MTBF mide cuánto tiempo suele funcionar un sistema antes de fallar, por lo que es ideal para evaluar la fiabilidad a largo plazo y prevenir fallos en aplicaciones críticas. Un MTBF alto indica un diseño y mantenimiento robustos, lo que reduce la frecuencia de las interrupciones. Sin embargo, no tiene en cuenta la rapidez con la que un sistema puede recuperarse cuando se producen fallos.
En cambio, el MTTR se centra en la velocidad de recuperación, midiendo el tiempo medio para restaurar un sistema después de que se produzca un fallo. Es fundamental en entornos donde el tiempo de inactividad es costoso. Un MTTR bajo garantiza un impacto operativo mínimo, pero no tiene en cuenta la frecuencia de los fallos.
Para un rendimiento óptimo, ambas métricas deben utilizarse conjuntamente: un MTBF alto minimiza los fallos, mientras que un MTTR bajo garantiza una rápida recuperación. Priorice el MTBF para la prevención de fallos en sistemas de alto riesgo o el MTTR para operaciones de ritmo rápido, pero alinéelos siempre con sus objetivos específicos y las normas del sector.
¿Qué es se considera un buen MTBF?
Un buen MTBF es relativo y depende de muchos factores. Un MTBF más alto indica una mayor fiabilidad porque demuestra que el equipo puede funcionar durante periodos más largos entre fallos. Sin embargo, el MTBF varía en función del tipo de activo, sus condiciones de funcionamiento, su antigüedad, las prácticas de mantenimiento y otros factores. Los activos con más piezas móviles y mayor complejidad también pueden tener un MTBF más bajo simplemente porque tienen más oportunidades de fallo.
Para determinar un "buen" MTBF, consulte las normas del sector o las especificaciones del fabricante para obtener puntos de referencia adaptados a su equipo. Mejor aún, analice sus propios datos sobre activos similares en condiciones comparables para establecer objetivos realistas. Combine el MTBF con métricas como el MTTR para obtener una imagen más completa de la fiabilidad.
Cómo mejorar el tiempo medio entre fallos
Hay algunas formas clave de aumentar el MTBF de un activo.
- En primer lugar, asegúrese de que sus datos son precisos utilizando un sistema fiable como el software GMAO . Necesitas muchos datos precisos y fiables para garantizar las métricas más actualizadas.
- A continuación, ponga a trabajar sus métricas. Utilice el MTBF calculado para crear un plan de mantenimiento preventivo a medida para cada activo. Ahora tiene una buena idea de cuándo debería fallar su equipo, así que planifique las acciones de mantenimiento necesarias antes de que llegue ese momento.
- Cuando los equipos fallan, es una buena práctica realizar un análisis de causa raíz (ACR). Si se realiza correctamente, el análisis de causa raíz puede ayudarle a comprender el problema subyacente que ha provocado el fallo de su activo. Esto le ayudará a determinar exactamente qué tareas de mantenimiento debe realizar su equipo para evitar futuros fallos.
- Por último, la implantación de un programa de mantenimiento predictivo es una de las mejores formas de mejorar el MTBF. El mantenimiento predictivo aprovechalos datos de monitoreo de condición para identificar los fallos de los activos en las fases más tempranas, mucho antes de que provoquen una avería. El mantenimiento predictivo proporciona un sistema de alerta temprana que protege contra los fallos de la máquina y mejora el tiempo medio entre fallos.
Un buen GMAO - como eMaint - mejora el MTBF facilitando la recogida de datos, ayudando a establecer las prioridades de mantenimiento y analizando los datos de monitoreo de condición . El resultado es un enfoque de mantenimiento predictivo racionalizado que conduce a una mayor eficiencia y una fuerte reducción del tiempo de inactividad, la mejora de los KPI como MTBF, y menores costes de mantenimiento.
Hable con un especialista para saber cómo un GMAO puede ayudar a realizar un seguimiento de los KPI de mantenimiento y mejorar las prácticas de mantenimiento de su equipo.